Мастерская аналитика. Как думать до первых данных
И превратить хаос требований заказчика в связанную карту метрик


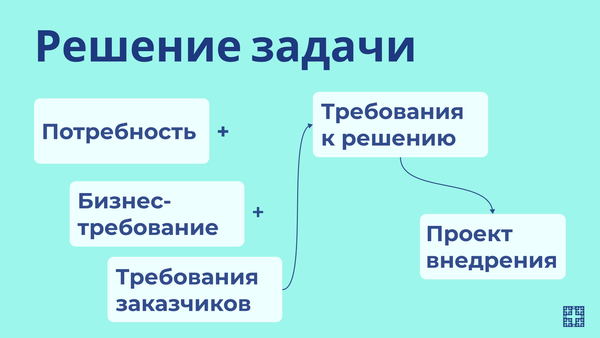
Вам прилетает задача: нужен дашборд для руководства. На руках — пачка метрик от нескольких стейкхолдеров, противоречивые приоритеты и ощущение, что начать можно откуда угодно (и потому непонятно, откуда).
Нас всегда учили, как строить из этого: как собрать данные, как разместить на дашборде, из каких визуализаций собрать картинку. Но не учат брать ответственность за структуру и расстановку приоритетов. Обычно это остаётся либо на откуп заказчикам, что почти гарантированно превращается в доработки или работу в стол. Либо нарабатывается годами и остаётся на уровне интуиции.
В прошлой статье я назвал этот этап макро-повествованием. Внутри — две задачи: что показать (архитектура) и как расположить (повествование). Эта статья — про первую.
Мастерская — попытка превратить аналитическое мышление в алгоритм. Чтобы на следующей встрече вы не оправдывались «ну вы же сами просили», а объясняли: вот почему эти метрики, а не те, вот как они связаны, и вот что мы с ними будем делать.
У каждого шага — интерактивная форма, заполняйте под свой проект. Пример на подписочном бизнесе, но метод для любой предметки. Повествование — во второй части.
Если вы сейчас потянулись к кнопке избранного, чтобы вчитаться потом и всё заполнить, — остановитесь. Мы оба знаем, что этого не случится. Вы отвлечётесь, жизнь направит внимание в другое русло, а через полгода вы такие: да, классная штука, надо обязательно дойти до неё, вот в отпуске..!
Не откладывайте. Прочитайте сейчас хоть как-то, поймите концепцию — подсознание запомнит куски, и это начнёт приносить пользу. Для этого я всё и создавал.
На старте выделите два часа
Когда начнёте раскладывать вопрос на метрики, будет соблазн копать бесконечно: а что, если разложить по каналам? А может, по сегментам? А когорты? Каждый вопрос порождает ещё три. Сколько времени дадите — столько и потратите (закон Паркинсона — и за десятилетия ничего не изменилось).
У меня самого было так не раз: закапывался на недели, а потом, оборачиваясь назад, понимал — осознания с первых итераций дали мне 80% структуры. Остальное уточнялось по ходу.
Поэтому поставьте таймер на два часа. Серьёзно. Этого хватит, чтобы превратить хаос записей после интервью в связанное дерево метрик.
Итак, впереди четыре шага: получим один вопрос из хаоса записей → разложим его на дерево метрик → углубим сегментами и отфильтруем → свяжем метрики в систему.
Получаем один вопрос из хаоса записей
Три интервью позади. CEO хочет видеть revenue и unit-экономику, PM — retention по когортам, маркетинг — стоимость привлечения и конверсию воронки. В заметках 40 метрик, и каждая выглядит важной (потому что для кого-то она и правда важная). Выбросить страшно — вдруг на демо спросят «а где churn rate?». Оставить всё — получится не дашборд, а таблица в Excel на три экрана.
Первый порыв — начать сортировать. Но проблема не в количестве метрик, а в том, что за каждым запросом стоит задача, которую человек пытается решить. Пока вы не поймёте, зачем им эти графики, вы будете приоритизировать слова, а не смыслы.
Лучший вопрос, который можно задать стейкхолдеру на интервью, — «а что дальше?». Человек называет метрику — вы спрашиваете: окей, увидишь число, что будешь делать? И раскручиваете до действия.
PM (приходит после третьего месяца падения retention)
CEO (готовится к совету директоров)
Маркетинг (запустил два новых канала)
Смотрите, что получается. У каждого ситуация, которая запускает вопрос. Данные, которые хочет увидеть. И действие, ради которого всё затевалось.
Это вариация Jobs to Be Done из продуктовой разработки (буквально — «работа, для которой нанимают продукт»). Формула работает для дашбордов ровно так же, как для фичей: понять, что человеку на самом деле нужно, а не что он попросил.

Кто главный герой вашего дашборда
У каждого стейкхолдера своя задача, и дашборд не может обслуживать все одинаково хорошо. Что поставить на первый экран? До какой глубины копать? Какой срез сделать основным?
Герой дашборда — это критерий, который разрешает эти споры. Приоритет, от которого отталкиваются все остальные решения. Остальные стейкхолдеры не страдают — их потребности решаются через фильтры, отдельные view или отдельный дашборд.
Как выбрать героя? Смотрите на список задач и спросите: у кого боль острее? У кого решения прямо сейчас принимаются вслепую: данные разрозненные, выводы держатся на интуиции, а последствия ошибки ощутимые. Где разрыв между «есть данные» и «понимаю ситуацию» максимальный — там инструмент даст эффект сразу.
А потом второй вопрос: кто решает и делает? Чьи решения реально меняют ситуацию, и как часто? CEO определяет стратегию раз в квартал. PM меняет онбординг, приоритеты, эксперименты каждую неделю. Кто живёт в дашборде каждый день — тот кандидат.
Вернёмся к нашим подпискам. CEO — главный стейкхолдер, и первый порыв: делать для него.
Боль острее у PM — его команда не выполняет план по вовлечённости, а данные для диагностики разрозненные. Действовать тоже будет PM: менять онбординг, двигать приоритеты, запускать эксперименты. Главный герой — не тот, кто выше по должности, а тот, чья работа меняется от наличия инструмента. В нашем случае это Product Manager.
Возьмём JTBD героя: «Когда monthly retention падает третий месяц подряд, хочу видеть, на каком этапе жизненного цикла отваливаются пользователи и в каких сегментах, чтобы понять, это онбординг сломался или мы теряем зрелых, и направить команду на конкретный участок воронки».
Из этой формулировки вытаскивается центральный вопрос — буквально за три хода:
Этот вопрос — фильтр. Стейкхолдер приходит с метрикой — вы спрашиваете себя: как она помогает ответить? Если можете проследить цепочку (допустим, Day-7 Retention по каналу привлечения показывает, где ломается онбординг, а это часть ответа), вы включаете метрику и формулируете связь вслух.
А если не можете — «Мы тут про удержание по этапам. Ты хочешь эффективность каналов — это к Пете, у него дашборд по маркетингу». И вот уже первая победа: не сделали лишнюю работу, не усложнили архитектуру инструмента костылём, но при этом решили запрос. Стейкхолдер получил ответ, куда идти, а не отказ. Центральный вопрос расставляет всё по местам.
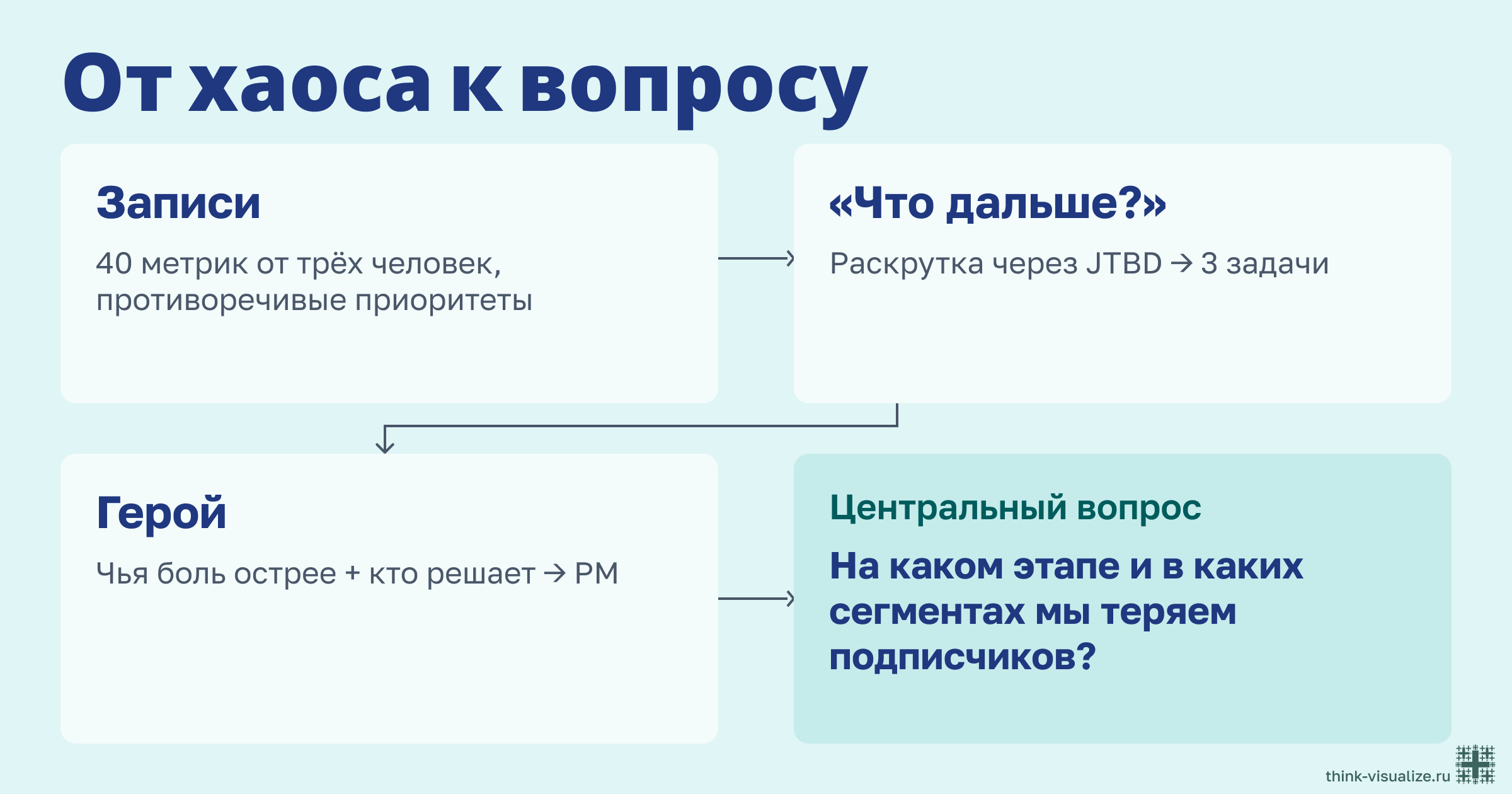
Весь этап на одной картинке: от десятка противоречивых голосов — к одному вопросу, который управляет системой.
Один вопрос есть. Теперь из него нужно вырастить метрики — разложить так, чтобы ничего не упустить и ничего не продублировать.
Разложите вопрос на дерево метрик
Один вопрос порождает десяток подвопросов, и каждый требует своей метрики. Если начнёте набрасывать их хаотично — «а давайте ещё конверсию в триал, а вот sticky factor, а может retention по каналам» — получите ровно тот хаос, от которого только что избавились. Только теперь это хаос метрик вместо хаоса требований.
Нужен способ разложить вопрос так, чтобы ничего не пропустить и ничего не посчитать дважды. На моей практике работают два метода:
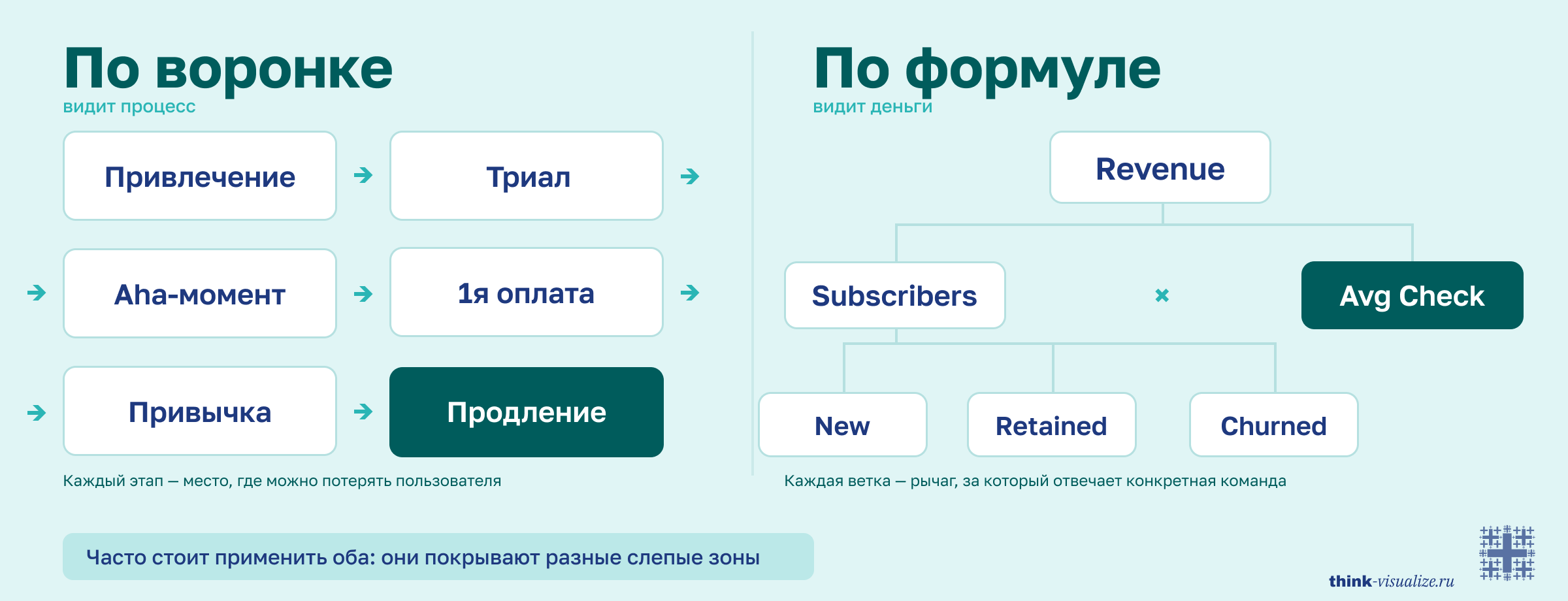
Когда в вопросе есть путь, этапы, последовательность. «На каком этапе теряем?» → воронка.
Когда в вопросе есть число, которое раскладывается на части. «Почему упало?» → формула.
Часто стоит применить оба: они покрывают разные слепые зоны и потом сшиваются в одну модель.
Метод 1. По воронке
В вопросе «на каком этапе теряем подписчиков?» слово «этап» — это путь. Последовательность состояний, через которую проходит пользователь. Задача — разложить путь на шаги и спросить, где именно люди сходят с дистанции.
Готовых воронок в интернете — десятки. Проблема в том, что все они описывают чей-то чужой продукт. Копировать чужую воронку — всё равно что надеть чужие очки: вроде видно, но не в фокусе.
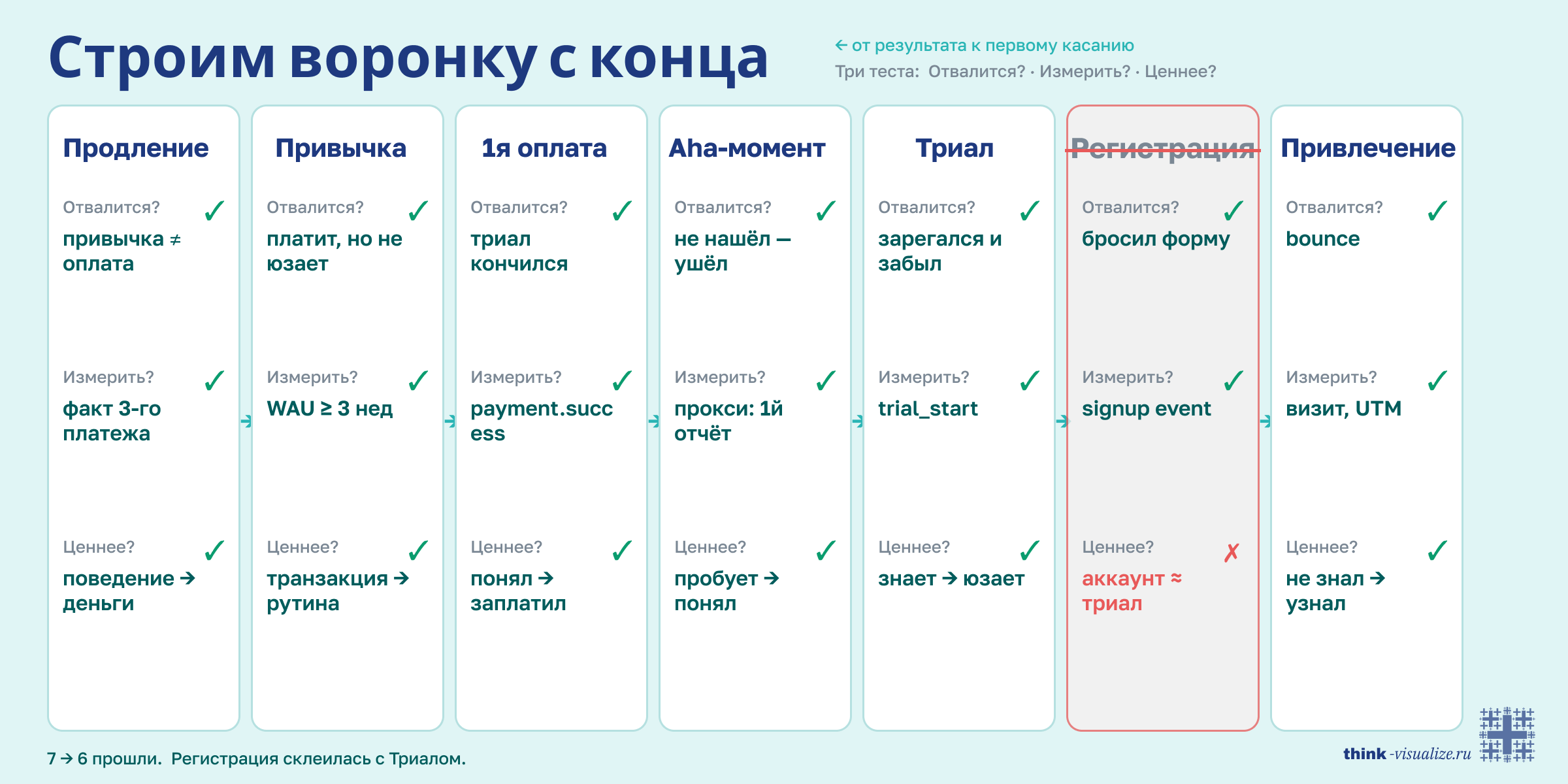
Стройте свою воронку с конца.
Не «пользователь зарегистрировался, потом...», а наоборот — «какое конечное состояние означает успех?» Для подписок это, допустим, «платит третий месяц подряд». Окей, а что должно случиться прямо перед этим? А перед тем?
Вы разматываете цепочку от результата к первому касанию, и каждый шаг — это смена состояния пользователя. Не действие в интерфейсе (кликнул кнопку), а именно смена состояния (был случайным посетителем — стал заинтересованным).
Как понять, что шаг настоящий, а не лишний? Три вопроса-теста.
- Можно отвалиться? Если на этом шаге пользователь не может уйти — это не отдельный шаг, а часть предыдущего.
- Можно измерить? Если нет события или признака перехода — шаг существует только в вашей голове.
- Стало ценнее? Если два соседних шага дают одинаковую ценность — склейте их в один.
Воронка — это не обязательно путь пользователя. Это любой процесс с последовательными состояниями:
- Заказ на складе: приём → сборка → отгрузка → доставка
- Кредит в портфеле: выдача → первый платёж → просрочка → дефолт
- Кандидат в найме: отклик → скрининг → интервью → оффер
Принцип тот же: стройте от конца, проверяйте каждый шаг тремя тестами.
Для подписочного бизнеса у меня получается примерно так:
привлечение → регистрация → триал → aha-момент (пользователь впервые видит ценность продукта) → первая оплата → привычка → продление.
Семь шагов, каждый проходит все три теста.
В e-commerce воронка другая: первый визит → добавление в корзину → покупка → повторная покупка → регулярный покупатель. Шаги разные, три теста — те же.
И вот тут воронка начинает работать. Вспомните, с чего начинали: «теряем подписчиков, непонятно где». Теперь у вас конкретика: триал → aha-момент — 33%. Две трети пользователей уходят, так и не поняв ценности продукта. Это уже не ощущение «что-то не так» — это конкретный участок с конкретной метрикой, по которой можно действовать.
Это был первый метод. Если у вас в голове сейчас плотно — нормально, воронка требует концентрации. Второй метод проще механически, но вскрывает другой слой.
Метод 2. По формуле
Второй тип вопросов звучит иначе: не «где в процессе теряем», а «почему упало» или «из чего состоит число». Слово «этап» подсказывало воронку. А слово «почему» подсказывает формулу.
Возьмите метрику. Допустим, Revenue. Задайте один вопрос: как она считается?
Revenue = Subscribers × Avg Check (AOV)
Два числа. И это уже два отдельных вопроса: подписчиков стало меньше? Или каждый платит меньше? Вы ещё ничего не считали, но уже видите два направления, которых не было, пока вы смотрели на Revenue как на одно число.
Дальше тем же способом. Количество платящих — откуда берётся?
Subscribers = New + Retained − Churned
Три числа. Каждое — отдельный вопрос для отдельной команды: маркетинг привлекает новых, продукт удерживает старых, support работает с оттоком.
Для e-commerce тот же принцип:
- GMV = Orders × AOV
- Orders = New + Repeat
Метрики другие, вопрос «как считается?» — тот же.
Каждый раз, когда вы раскладываете число на части, проверяйте двумя вопросами.
- Независимы? Можно ли крутить одно, не ломая другое?
- Управляемы? Есть ли конкретный человек или команда, которая за это отвечает?
Revenue = Subscribers × Avg Check — работает: наймите маркетолога, он увеличит подписчиков, не трогая тарифы. Два рычага. А вот Revenue = Users × ARPU — тавтология: ARPU = Revenue / Users, вы поделили число на само себя. Avg Check — рычаг, ARPU — математическое эхо.
Subscribers = New + Retained − Churned — за новых отвечает маркетинг, за удержание — продукт, за отток — support. Если за часть никто не отвечает — она неуправляема.
Два-три уровня глубины достаточно. Но есть ловушка: иногда «как считается?» даёт не разложение, а определение. Если вы в банке и разложили «доля просроченных кредитов = просроченные / все» — это правда, но не помогает понять, почему просрочка растёт. Вы описали метрику, а не разложили её.
Копайте глубже. За той же просрочкой стоит: вероятность дефолта (зависит от скоринга), потери при дефолте (зависит от коллекшн), размер риска (зависит от лимитной политики). Три команды, три рычага, три вопроса. Разложение настоящее, когда за каждой частью стоит конкретный человек, который может её двигать.
В чём сила формулы по сравнению с воронкой? Она вытаскивает измерения, к которым воронка слепа. Воронка видит путь пользователя — привлечение, активацию, удержание. Но она не видит деньги: микс тарифов, средний чек, баланс притока и оттока. Формула разворачивает число и показывает то, что спрятано внутри.
Когда узел — ещё не метрика
Формульные узлы — уже метрики. Subscribers, Avg Check, New, Churned — каждый можно посчитать прямо сейчас.
С воронкой сложнее. «Регистрация» — метрика очевидна. А «aha-момент»? Это не число, это состояние. Из него можно извлечь Time to Key Action, Feature Discovery Rate, Day 1 Retention — и каждая подсветит разную грань. Какую выбрать?
Спросите себя: «Какие наблюдаемые признаки докажут, что этот переход работает здорово — или что он болен?»
Возьмём «триал → aha-момент». Если здорово — пользователь быстро находит ключевую функцию и возвращается на следующий день. Если болен — регистрируется, тыкает в два экрана и пропадает. Из этой картины выпадают три метрики-кандидата: Time to Key Action (сколько минут до первого значимого действия), Feature Discovery Rate (какую долю ключевых функций нашёл за первую сессию), Day 1 Retention (вернулся ли вообще).
Вы не вытаскивали их из памяти — вы вывели их из наблюдаемого поведения, поэтому сможете объяснить, почему эта метрика здесь. Не «так принято» и не «PM попросил», а «она отвечает на вот этот вопрос, а вопрос отвечает вот этой цели». Цепочка от цели до метрики — прозрачная, и каждое решение в ней аргументированное.
Сверяем дерево с исходным списком
Вернитесь к тем 40 метрикам из записей стейкхолдеров. Часть вы переоткрыли — они уже на дереве. Часть не вписалась, и теперь понятно почему. А часть метрик на дереве вы бы никогда не нашли в том списке, потому что стейкхолдеры их не просили. Это и есть результат: дерево порождает метрики, которые невозможно получить сортировкой хотелок.

Дерево построено — проверьте его. Принцип простой: каждый аспект вопроса покрыт ровно один раз. В консалтинге это называют MECE — mutually exclusive, collectively exhaustive. На практике это три теста.
Тест на полноту: сложите или перемножьте дочерние узлы — получается ли родитель? Revenue = Subscribers × Avg Check — сходится. А если у вас «привлечение, удержание, монетизация» и вы не можете из них арифметически собрать целое — значит, что-то пропущено или уровни смешаны.
Тест на пересечение: может ли одна метрика попасть в две ветки одновременно? Если «реферальные пользователи» сидят и в «новых», и в «вернувшихся» — у вас двойной счёт. Две команды будут оптимизировать одних и тех же людей и не знать об этом.
Тест на действие: каждый лист дерева — это метрика, за которую кто-то отвечает. Если за лист никто не отвечает — он бесполезен. Если за один лист отвечают две команды — будет конфликт.
Это не гарантия идеальности — в системах с обратной связью чистое MECE невозможно. Но эти три теста ловят 90% ошибок до того, как они станут проблемой на демо.
Каркас готов. Дерево построено, MECE проверено. Осталось два действия: разрезать по сегментам и отфильтровать. Самое сложное позади.
Углубите и отфильтруйте
Дерево описывает «среднюю температуру по больнице». А среднее может ввести в заблуждение.
Допустим, у вашего подписочного сервиса есть Enterprise- и SMB-клиенты. Churn rate по компании снизился с 8% до 6%. Зелёная стрелка на слайде, CEO доволен.
Но разрежьте по типу клиента. Enterprise churn вырос с 2% до 5% — самый ценный сегмент деградирует. А SMB churn упал с 12% до 6.5%. Поскольку SMB-клиентов в три раза больше, их улучшение арифметически перевесило провал Enterprise. Среднее красивое, реальность — нет.
Это не единичный случай. Вот Datasaurus Dozen — 13 совершенно разных распределений с одинаковыми средними, дисперсиями и корреляциями:
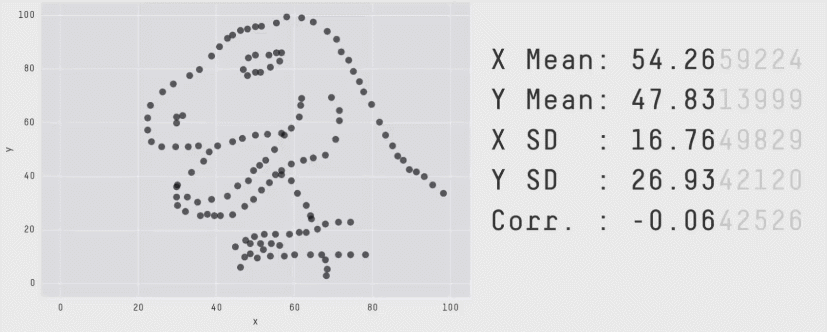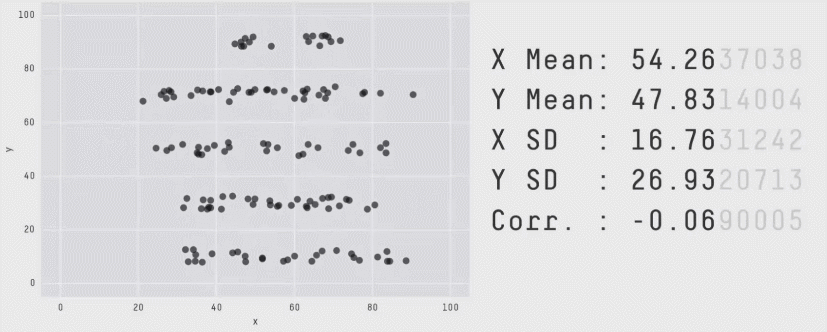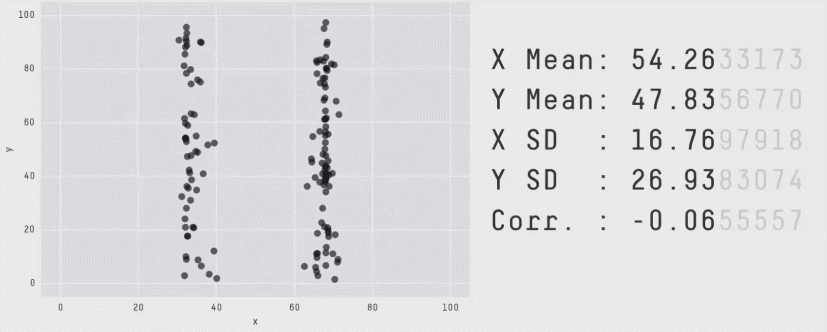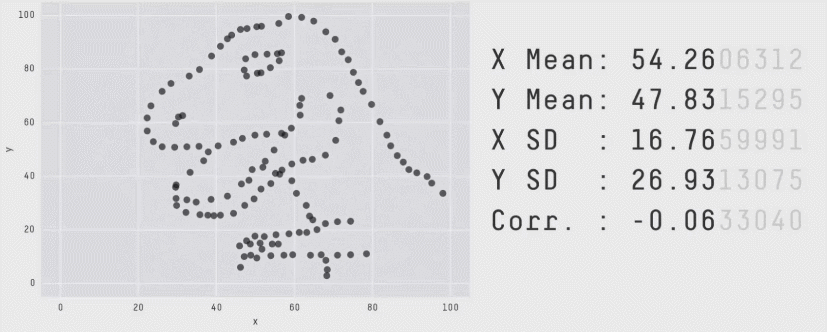
Вывод простой: одного числа недостаточно. Чтобы понять, что происходит, нужно разрезать по сегментам.
И даже когда среднее не обманывает, оно не говорит, где действовать. Retention упал на 4 пункта. У кого? У новых пользователей, которые не прошли онбординг? У тех, кто сидит на бесплатном тарифе и никогда не платил? У мобильных, где вы полгода не обновляли приложение? Без сегментов метрика говорит «что-то не так», но не говорит «у кого» и «где копать». Сегменты превращают сигнал тревоги в адрес проблемы.
Воронка показывает, на каком этапе процесса ломается. Формула показывает, из чего состоит результат и где рычаги. Сегменты разрезают и то, и другое по осям, которые важны для бизнеса. Это не третий метод декомпозиции — сегменты не порождают новые ветки дерева, а разрезают существующие. То же дерево, но под другим углом.

Как выбирать, по каким осям резать? Измерений можно придумать десятки: география, платформа, канал привлечения, тариф, размер компании, день недели регистрации. Нужен фильтр.
Измерение — это ось, по которой в бизнесе уже существуют разные стратегии, разные команды или разная экономика. Маркетинг выделяет бюджет по каналам — канал привлечения = измерение. Продукт держит отдельную команду под iOS и отдельную под Web — платформа = измерение. Enterprise и self-serve живут в разных циклах продаж с разным LTV — тип клиента = измерение. Принцип структурный: он работает без данных, до того как вы открыли любой дашборд.
Соблазн нарезать всё по всем осям понятен. Но не каждое измерение применимо к каждому узлу: канал привлечения важен для конверсии в триал, но почти не влияет на retention через полгода. Выбирайте 3-5 осей для каждого узла, не больше.
А если измерений набирается слишком много, скорее всего ваш центральный вопрос склеивает несколько разных задач — и вам нужно не одно дерево с двадцатью измерениями, а два дерева с тремя.
Не каждая метрика заслуживает места на дашборде
К этому моменту у вас на дереве накопились метрики-кандидаты: из воронки, из формулы, из сегментов. Часть из них станет ключевыми метриками дашборда, часть уйдёт в drill-down, часть окажется шумом. Три вопроса к каждой метрике помогут отделить ключевые от шума.
Для каждой метрики-кандидата пройдитесь по трём критериям.
Есть ли рычаг? Можно ли связать метрику с конкретным действием команды — не со стратегией, а с тем, что кто-то сделает на следующей неделе?
«Количество скачиваний» — зависит от бюджета, ASO, сезонности. Рычага у продуктовой команды нет. «Конверсия из регистрации в первое ключевое действие» — рычаг очевиден: онбординг, UX, подсказки.
Реагирует ли вовремя? Успеете ли увидеть результат до следующего цикла планирования?
LTV подписчика — 6-12 месяцев до достоверного расчёта. Вы выкатили новый онбординг в январе, а узнали, что он повлиял на LTV, в декабре. Retention Day 30 покажет сдвиг через пять-шесть недель.
Можно ли объяснить за 30 секунд? Не коллеге-аналитику, а продакту, который будет смотреть на метрику каждый день.
Health Score из пяти нормализованных компонентов — прекрасная аналитическая модель, но ключевой метрикой дашборда ему не быть.
Метрика не набрала по всем трём — не выбрасывайте. Она может работать на уровне drill-down или как стратегический ориентир.

Тест «злой гений»
Представьте, что за оптимизацию каждой ключевой метрики взялся злой гений — умный, изобретательный, но с одной целью: сделать число красивым любой ценой. Что он сломает?
Оптимизируете конверсию из триала в первую оплату? Злой гений укоротит триал до трёх дней и добавит попап «Заплати или потеряешь данные» — конверсия взлетит, но пользователи будут платить с отвращением и уйдут через месяц. Значит, контрметрика — Retention Day 30 после оплаты.
Растёт retention? Злой гений заблокирует экспорт данных и усложнит отмену подписки — пользователи останутся, но не потому, что довольны, а потому, что не могут уйти. Контрметрика — NPS или CSAT: если retention растёт, а удовлетворённость падает, вы не удерживаете, а держите в заложниках.
Контрметрика — это не вторая метрика «для полноты». Это страховка от перекоса. Она не должна расти — она должна не падать, пока вы двигаете основную. Одна-две контрметрики на каждую ключевую, не больше. Если контрметрик получается пять — вы пытаетесь застраховаться от всего, а это невозможно и бессмысленно.

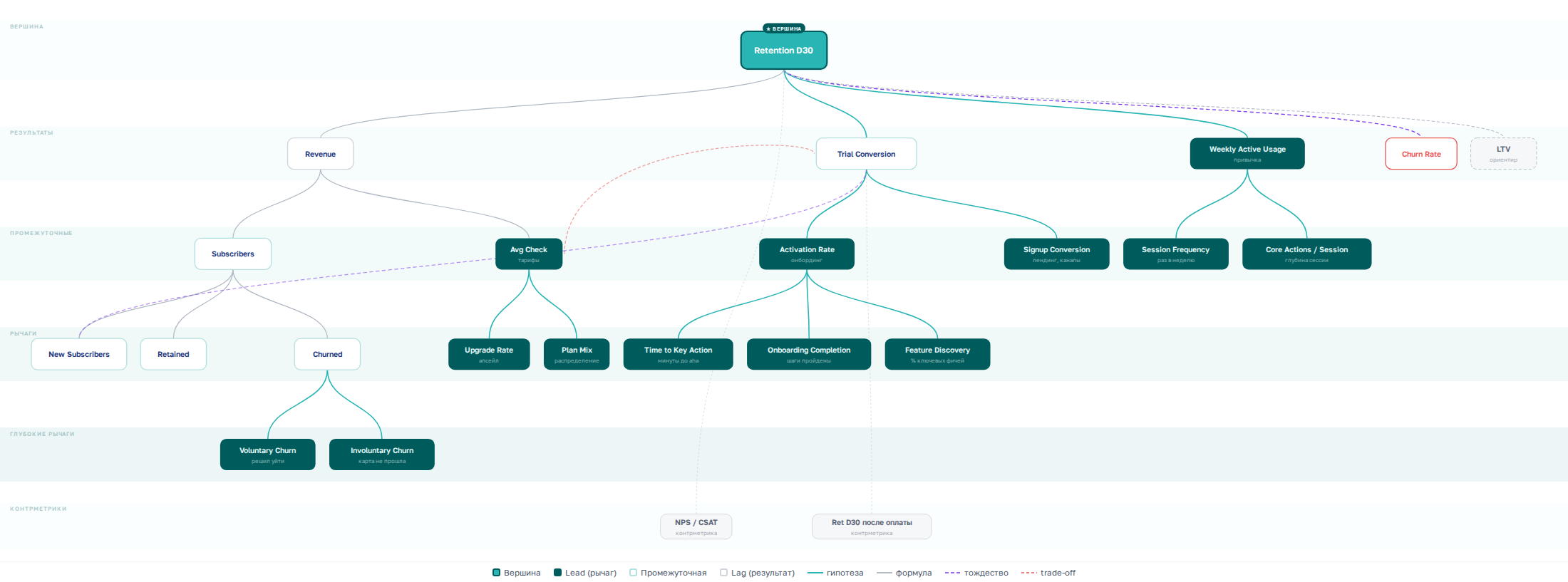
Дерево построено: вопрос разложен на подвопросы, подвопросы — на метрики, метрики расставлены по приоритетам. До сих пор мы разбирали, теперь обратная операция: соединяем то, что разложили, и открываем связи, которых не было видно в дереве.
Свяжите метрики в систему
Ключевые метрики и контрметрики на месте. Дерево построено из логики вопроса — вы разложили его на части и проверили. Но у вас как у аналитика есть кое-что ещё: понимание того, как бизнес работает.
Дерево показывает, из чего состоит вопрос — иерархию. Но в бизнесе метрики влияют друг на друга не только сверху вниз: активация влияет на удержание, скорость онбординга — на конверсию, цена и конверсия тянут в разные стороны. Эти связи в дереве не видны. И пока они в голове, их невозможно проверить, невозможно оспорить, невозможно использовать.
Сделайте это явным. Начните с метрик в нижней части дерева — тех, на которые команда влияет напрямую. Для каждой спросите:
На какой результат она влияет и почему я так думаю?
Вы обнаружите три типа связей.
Гипотезы
Это и есть запекание аналитического мышления: ваши предположения о том, как устроена механика бизнеса, вытащенные из головы и зафиксированные. Activation Rate → Trial Conversion — потому что человек, увидевший ценность, скорее заплатит. Activation Rate → Retention D30 — потому что хорошо активированный пользователь дольше остаётся.
Тест: можете дописать «потому что конкретный механизм]» — гипотеза есть. Не можете — связь кажущаяся.
Тождества
Одно и то же явление, посчитанное по-разному. Прошедшие триал в воронке и новые подписчики в формуле — это одни и те же люди. Retained в формуле — обратная сторона Churned.
Тождества прошивают воронку и формулу насквозь: два параллельных дерева оказываются одной системой. Если тождество не зафиксировано, две команды будут считать одно и то же разными способами — и на демо всплывёт: «у тебя 45%, а у меня 42%».
Trade-off’ы
Метрики, которые тянут в разные стороны. Поднимаете средний чек — конверсия в триал падает, потому что цена пугает.
Trade-off — это не проблема, которую нужно решить, а ограничение, которое нужно видеть. Если trade-off не на графе, вы узнаете о нём, когда одна метрика «необъяснимо» упадёт после того, как вы оптимизировали другую. А когда он на графе — вы принимаете решение осознанно: да, конверсия упадёт, но средний чек вырастет сильнее.
Если на один переход или компонент формулы приходится несколько метрик-кандидатов, выберите одну как узел графа, остальные станут drill-down. Граф работает на уровне решений, диагностика — уровнем ниже.
Нарисуйте все три типа стрелок — и дерево превратится в связный граф. Дерево показывало логику вопроса — сверху вниз. Граф показывает физику бизнеса — по горизонтали и диагонали.
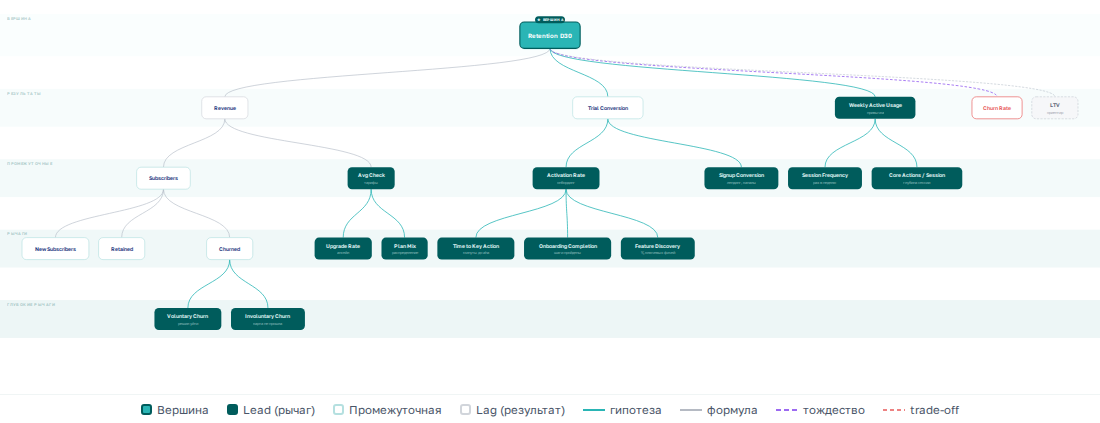
Lead и lag: рычаги и результаты
В графе сразу видна структура, которой не было в дереве. Одни узлы — те, в которые стрелки входят, но почти не выходят: Revenue, LTV, Churn Rate. Это результаты. Вы на них смотрите, но не можете крутить напрямую — как спидометр в машине. Другие узлы — те, из которых стрелки выходят: Time to Key Action, Activation Rate, Avg Check. Это рычаги — те самые управляемые части формулы из Шага 2, только теперь видно, на что именно они влияют. В литературе первые называют lag-метриками, вторые — lead.
Если на дашборде одни lag-метрики, вы построили зеркало заднего вида. Команда видит, что произошло, но не понимает, что делать. Если одни lead — пульт управления без приборной панели: крутите рычаги, не зная, долетели ли изменения до результата.
Амазон управляет бизнесом именно так: ширина ассортимента, цена, скорость доставки — это lead-метрики, на которых сфокусированы команды. Revenue — следствие, которое проверяют, но не оптимизируют напрямую.
Теперь посмотрите на верхушку графа. Туда, куда стекаются стрелки. Там две-три lag-метрики, в которые в итоге упирается всё остальное. На первом экране дашборда нужна вершина — число, которое отвечает на вопрос «у нас дела хорошо или плохо?». Без неё двенадцать графиков рассказывают двенадцать историй, и непонятно, что со всем этим делать.
Как выбрать вершину? Два теста.
Отражает ли метрика ценность для клиента — или только для бизнеса? Revenue растёт и когда клиент получает пользу, и когда форма отмены подписки спрятана за пятью экранами, а горячая линия работает с 2 до 3 ночи по средам. Метрика бизнеса наверху — и через полгода команда оптимизирует число, а не опыт.
Насколько дорого её накрутить? Мы уже играли в злого гения — тогда спрашивали «что он сломает». Теперь — «как дорого ему обойдётся». Activation Rate — засчитать любой клик, дёшево. Retention Day 30 — нужно, чтобы люди реально возвращались, дорого. Чем дороже накрутка — тем надёжнее вершина.
Если у дашборда два принципиально разных ритма — ежедневный и квартальный — вершин может быть две: одна быстрая и тактическая, другая медленная и стратегическая. Заставлять выбирать одну — значит оставить кого-то без ответа.
Вернёмся к нашим подпискам. Здесь ритм один — PM смотрит каждый день, CEO раз в неделю, но оба на одном уровне глубины. Вершина — Retention D30. Почему не Revenue? Мы уже разобрали: она не отличает здоровый рост от замаскированного. Retention D30 дороже накрутить — нужно, чтобы люди реально возвращались. А LTV? Она на графе как стратегический ориентир — посмотреть раз в квартал, сверить курс. Но вершина — Retention.
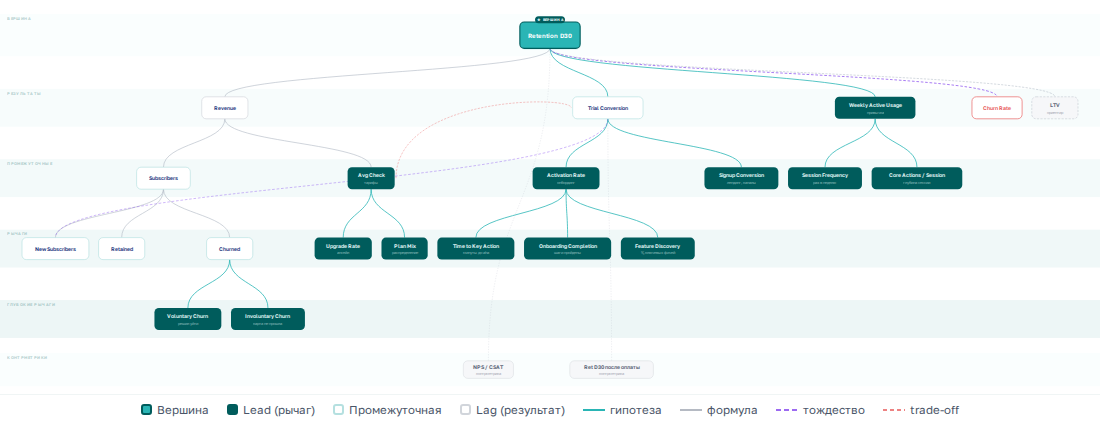
Дерево стало графом — это и есть ваша модель метрик. Размечена, с вершиной, с гипотезами на каждой стрелке. Вы систематизировали всё, что знаете о бизнесе, в одну структуру.
Что у вас на руках
Если вы дошли до этого места и делали упражнения по ходу, у вас готова аналитическая архитектура. Проверьте:
Пять артефактов. Все помещаются на одну доску в Miro или на один лист бумаги. Вы запекли своё аналитическое мышление в структуру — теперь его можно проверить, оспорить и передать другому.
Когда стоит пройти эти четыре шага:
- стейкхолдеры просят «ещё одну метрику», и у вас нет критерия сказать «нет»
- два отдела приходят с одной метрикой, но цифры разные
- дашборд зелёный, а бизнес при этом падает
- вы строите третий дашборд для одного и того же процесса
По моему опыту, именно такая карта позволяет не просто строить графики. Появляется аргумент сказать «нет». Из запросов вырастают системные инструменты, а не куча костылей. И вы начинаете предвосхищать своими решениями запросы заказчиков.
И что дальше?
Вы определили что показать. Но граф — это ещё не дашборд. Один и тот же граф будет по-разному читаться CEO и PM. Как превратить модель в интерфейс, где каждый находит свой ответ? Это задача макро-повествования — второго процесса, о котором мы говорили в начале.
Во второй части — как показать: последовательность, группировка, контекст. То, что превращает карту метрик в инструмент, которым удобно пользоваться.
Обсудить статью или задать вопрос — в Telegram.
Новые статьи — на почту
Без спама, раз в 1-2 недели.